An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Paper Explained)

#ai #research #transformers
Transformers are Ruining Convolutions. This paper, under review at ICLR, shows that given enough data, a standard Transformer can outperform Convolutional Neural Networks in image recognition tasks, which are classically tasks where CNNs excel. In this Video, I explain the architecture of the Vision Transformer (ViT), the reason why it works better and rant about why doublebline peer review is broken.
OUTLINE:
0:00 Introduction
0:30 DoubleBlind Review is Broken
5:20 Overview
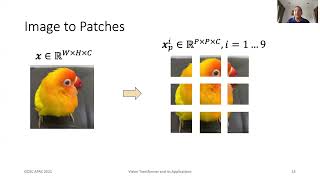
6:55 Transformers for Images
10:40 Vision Transformer Architecture
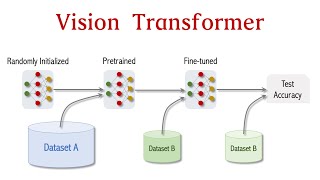
16:30 Experimental Results
18:45 What does the Model Learn?
21:00 Why Transformers are Ruining Everything
27:45 Inductive Biases in Transformers
29:05 Conclusion & Comments
Paper (Under Review): https://openreview.net/forum?id=YicbF...
Arxiv version: https://arxiv.org/abs/2010.11929
BiT Paper: https://arxiv.org/pdf/1912.11370.pdf
ImageNetReaL Paper: https://arxiv.org/abs/2006.07159
My Video on BiT (Big Transfer): • Big Transfer (BiT): General Visual Re...
My Video on Transformers: • Attention Is All You Need
My Video on BERT: • BERT: Pretraining of Deep Bidirectio...
My Video on ResNets: • [Classic] Deep Residual Learning for ...
Abstract: While the Transformer architecture has become the defacto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer can perform very well on image classification tasks when applied directly to sequences of image patches. When pretrained on large amounts of data and transferred to multiple recognition benchmarks (ImageNet, CIFAR100, VTAB, etc), Vision Transformer attains excellent results compared to stateoftheart convolutional networks while requiring substantially fewer computational resources to train.
Authors: Anonymous / Under Review
Errata:
Patches are not flattened, but vectorized
Links:
YouTube: / yannickilcher
Twitter: / ykilcher
Discord: / discord
BitChute: https://www.bitchute.com/channel/yann...
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: / yannickilcher488534136
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: / yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n


![[Classic] Deep Residual Learning for Image Recognition (Paper Explained)](https://i.ytimg.com/vi/GWt6Fu05voI/mqdefault.jpg)