
How to build custom Datasets for Text in Pytorch

In this video we go through a bit more in depth into custom datasets and implement more advanced functions for dealing with text. Specifically we're looking at a image captioning dataset (Flickr8k data set) with an image and a corresponding caption text that describes what's going on in the image. I think the general principles from this video can be utilized to any project you're working with when dealing with text data be it either translation, question answering, sentiment analysis etc. I also recommend taking a look at my Torchtext which can also be quite helpful and simplify the data loading process.
❤ Support the channel ❤
/ @aladdinpersson
Paid Courses I recommend for learning (affiliate links, no extra cost for you):
⭐ Machine Learning Specialization https://bit.ly/3hjTBBt
⭐ Deep Learning Specialization https://bit.ly/3YcUkoI
MLOps Specialization http://bit.ly/3wibaWy
GAN Specialization https://bit.ly/3FmnZDl
NLP Specialization http://bit.ly/3GXoQuP
✨ Free Resources that are great:
NLP: https://web.stanford.edu/class/cs224n/
CV: http://cs231n.stanford.edu/
Deployment: https://fullstackdeeplearning.com/
FastAI: https://www.fast.ai/
My Deep Learning Setup and Recording Setup:
https://www.amazon.com/shop/aladdinpe...
GitHub Repository:
https://github.com/aladdinpersson/Mac...
✅ OneTime Donations:
Paypal: https://bit.ly/3buoRYH
▶ You Can Connect with me on:
Twitter / aladdinpersson
LinkedIn / aladdinperssona95384153
Github https://github.com/aladdinpersson
OUTLINE:
0:00 Introduction
2:05 Overview of what we're going to do
4:05 Imports
5:20 Setup of Pytorch Dataset for loading Flickr
11:50 Setup of Vocabulary and Numericalization
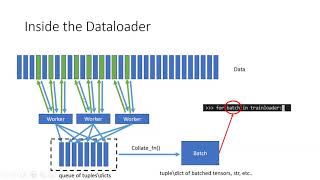
22:19 Creating Collate for Padding of Batch
25:20 Function for getting data loader
29:15 Running code & fixing couple of errors
33:09 Ending











![Build Your First Pytorch Model In Minutes! [Tutorial + Code]](https://i.ytimg.com/vi/tHL5STNJKag/mqdefault.jpg)














